“Yeah It’s on. ”
《统计学习方法》第1章 内容是一些理论和方法,虽然乏味了一些,但是很重要。
第1章 统计学习方法概论
[TOC]
1.1 什么是统计学习?又有那些方法?
统计(机器)学习是关于计算机给予数据 构建 概论统计模型,并运用模型对数据进行预测与分析一门学科。
统计学习的方法:
- 监督学习
- 半监督学习
- 非监督学习
- 强化学习
实现统计学习方法的步骤如下:
- 得到一个有限的训练数据集合
- 确定包含所有可能的模型的假设空间,即学习模型的集合
- 确定模型的选择的准则,即学习的策略
- 实现求解最优模型的算法,即学习的算法
- 通过学习方法选择最优模型
- 利用学习的最优模型对新的数据进行预测和分析
1.3 统计学习三要素
方法 = 模型 + 策略 + 算法
1.3.1 统计学习常用的损失函数:

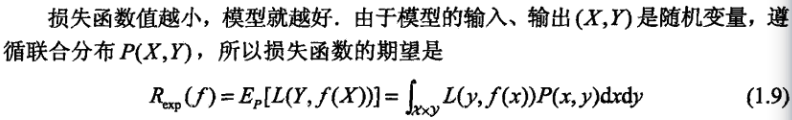
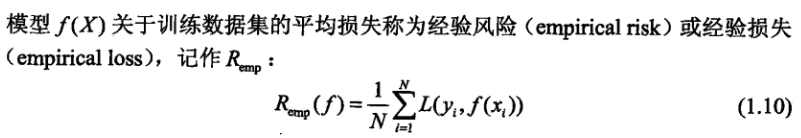
1.3.2 输入空间、特征空间与输出空间
输入空间、特征空间与输出空间
-
输入空间(所有输入的集合)
-
输出空间(所有输出的集合)
-
特征空间(输入空间变化后集合)
举个例子:对于一元二次函数模型:
| 输入空间为集合{x | x所有的取值},输出空间为集合{y | y所有的取值}。虽然该模型已经很简单,但是可以通过构建特征空间的方式,让模型简单化——构建**特征空间{f=x^2 | x属于输入空间}**,那么模型可以简化成: |
1.3.3 监督学习的两个基本策略:
-
经验风险最小化
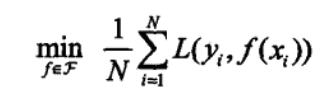
-
结构风险最小化(SRM)
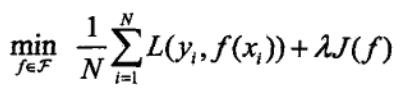 其中结构风险最小化,为了防止过拟合提出来的策略,等价于正则化是 经验风险最小化的基加上 表示模型复杂度的正则化项/罚项(regularizer/penalty term)。其中J(f)为模型复杂度,λ >= 0 ,是系数。
其中结构风险最小化,为了防止过拟合提出来的策略,等价于正则化是 经验风险最小化的基加上 表示模型复杂度的正则化项/罚项(regularizer/penalty term)。其中J(f)为模型复杂度,λ >= 0 ,是系数。
1.3.4 算法
算法是指学习模型 的 具体计算方法。统计学习基于训练数据,根据学习策略,从假设空间中选取最优模型,最后需要考虑用什么样的算法求解最优模型。
1.4 模型评估与模型选择
1.4.1 训练误差与测试误差
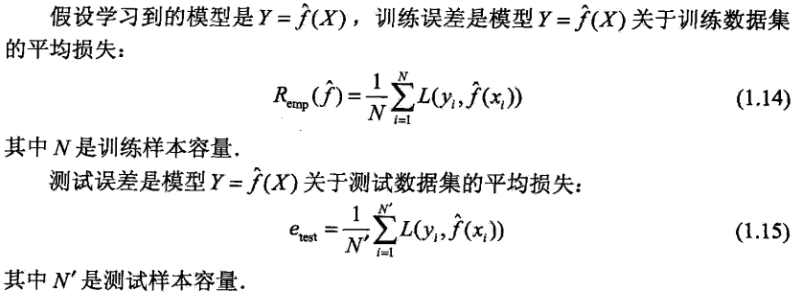
1.4.2 过拟合与模型选择
过拟合:学习时候选择的模型所包含的参数过多,以至于出现对训练集表现很好,但是测试集表现很差。一个简单图例如下:
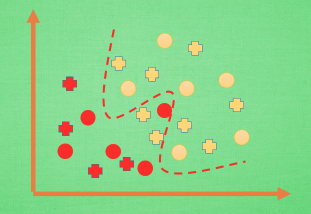 其中圆点表示训练数据,十字表示测试数据。该模型目的在于学习到一条可以区分不同类别的“边界线”。
其中圆点表示训练数据,十字表示测试数据。该模型目的在于学习到一条可以区分不同类别的“边界线”。
下图是训练误差和测试误差与模型复杂度的关系:
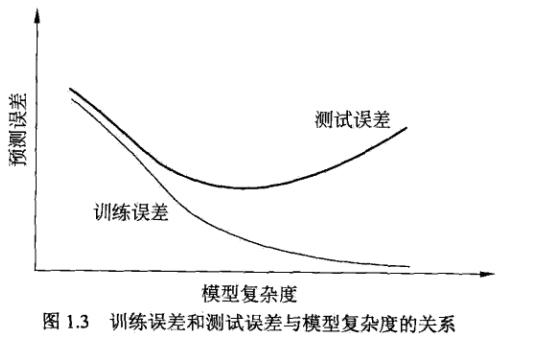
种常见的模型选择方法:
- 正则化
- 交叉验证
1.5 正则化与交叉验证
1.5.1 正则化
正则化模型复合奥卡姆剃刀(Occam’s razor)原理:所有可能选择的模型中,能够很少地解释已知一直数据并且十分简单才是最好的模型。
1.5.2 叉验证
随机将数据集分成三部分:训练集,验证集,测试集 训练集用于训练模型,验证集用于模型选择,测试集用于对最终学习的方法评估。
1.6 泛化能力
1.6.1 泛化误差
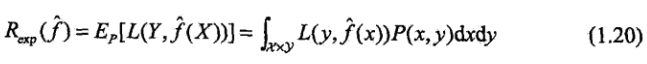
1.6.2 泛化误差上界

1.7 生成模型与判别模型
监督学习方法可以分为生成方法(generative approach)和判别方法(discriminative approach)。
1.7.1 生成方法
先学习P(X,Y),然后求出 P(X|Y),即模型:
生成方法特点:
- 生成方法可以还原出联合概率分布 P(X,Y),判别方法不能;
- 生成方法的学习收敛速度更快,当样本容量增加的时候,学到的模型可以更快的收敛于真实模型;
- 存在隐变量是,生成方法仍可以用,判别方法不能;
1.7.2 判别方法
判别法直接学习决策函数 f(x) 或者条件概率 P(X,Y)作为预测模型。 判别方法特点:
- 学习的准确率更高;
- 可以对数据进行抽象,定义特征并使用特征,简化学习问题;
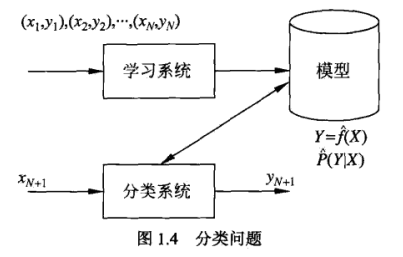
1.8 分类问题
分类器(classifier):监督学习从数据中学习一个分类模型或指分类决策函数。 分类(classification):分类器多新的输入进行输出预测 类(class):可能的输出
分类买模型如下图所示:
1.8.1 准确率
准确率是指我们的模型预测正确的结果所占的比例。正式点说,准确率的定义如下:
对于二元分类,也可以根据正类别和负类别按如下方式计算准确率:
PS: True Positive(真正,TP):将正类预测为正类数 True Negative(真负,TN):将负类预测为负类数 False Positive(假正,FP):将负类预测为正类数误报 (Type I error) False Negative(假负,FN):将正类预测为负类数→漏报 (Type II error)
1.8.2 精确率和召回率
精确率 精确率的定义如下:
1
*PS:表示在所有预测为正类别当中预测正确的比例。*
召回率 召回率的定义如下:
1
*PS:表示在所有正类别实例中,预测正确的比例。召回率越大,表示被误判的正类别越小。*
F1值
F1值是精确率和召回率的调和均值,公式如下:
即:
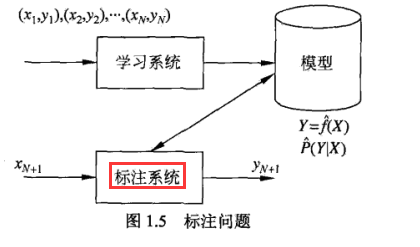
1.9 标注问题
可认为标准问题是分类问题的一个推广,标准问题是更复杂的结构预测(structure prediction)问题的简单形式。标注问题的输入是一个观测序列,输出十步一阁标记序列或状态序列。 标注常用的统计学习方法:隐马尔可夫模型,调节随机场structure prediction
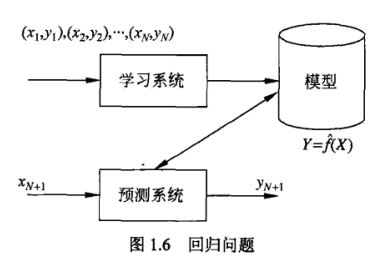
1.10 回归问题
回归问题用于预测输入变量(自变量)和输出变量(因变量)之间的关系(函数映射)。 损失函数是平方损失函数。