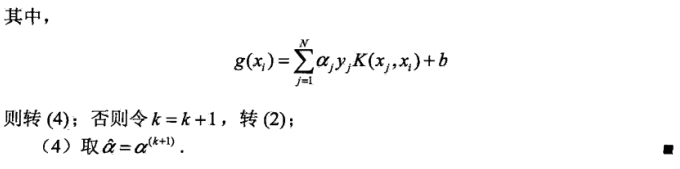“ Keep on going never give up.”
[TOC]
SVM,在我个人看来想是感知机的升级版。按之前的笔记《统计学习方法》(李航)读书笔记(二),大家应该发现感知机算法的最终结果依赖于初始值,初始值不同,得到的最终结果也不同——这是因为感知机算法只考虑构建一个超平面把2类实例分开就完事了,并未考虑如何分离才算最优。SVM不仅考虑要分开这2类数据,还考虑基于两类样本点之间的距离,给与一个相对公平公正的分离超平面。
下面想讲一个例子方便大家有一个笼统的概念。
例1:
下面是一个只有x轴的一维坐标轴,该轴同样存在原点,x轴正方向和x轴反方向,且该轴上分布了很多点:
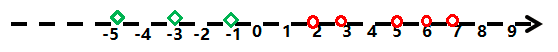
其中,红色的圆圈和绿色的菱形表示该坐标轴上的样本点,绿色的菱形坐标从左至右依次为:-5,-3,-1;红色的圈圈坐标从左到右依次为:2,3,5,6,7;此时,要求在坐标轴上找一个分割点,来分割红色的圆圈和绿色的菱形。
按照感知机的算法,在区间(1,2)任意一个点都满足要求,所以该问题对于感知机算法有无穷解。
而对于SVM,则需要基于距离计算出最优的分割点。根据上图,这个距离肯定是由最近的2个点(-1和2)决定的,因此找到2点中间那个点,也就是坐标点为:(-1+2)/2=0.5处,作为分割点,则最优。由此也可知,相同条件下,SVM有唯一解。
第七章 支持向量机
支持向量机(support vector machine,SVM)是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机。
支持向量机的学习算法是求解凸二次规划的最优算法。
有简至繁的迷行:线性可分支持向量机(linear support vector machine in linearly separable case)、线性支持向量机(linear support vector machine)以及非线性支持向量机(non-linear support vector machine)。
学习分类器方法:
-
条件:训练数据线性可分 方法:硬间隔最大化(hard margin maximization)
-
条件:训练数据近似线性可分 方法:软间隔最大化(soft margin maximization)
-
条件:训练数据线性不可分 方法:核技巧(kernel trick)及软间隔最大化
7.1 线性可分支持向量机与硬间隔最大化化
7.1.1 线性可分支持向量机
输入都由输入空间转化到特征空间,支持向量机的学习是在特征空间进行的。
感知机利用误分类最小的策略,求得分离超平面,不过这时候的解有无穷多个;线性可分支持向量机利用间隔最大化求最优分离超平面,解唯一。

7.1.2 函数间隔核几何间隔


7.1.3 间隔最大化
支持向量机学习的基本想法是求解鞥能够正确划分训练数据集并且几何间隔最大的分离超平面。
间隔最大化的直观解释:超平面以充分大的确信度对训练集进行分类(尤其是距离超平面距离最近的实例点)。
这个问题可以表示为下面约束最优化问题:
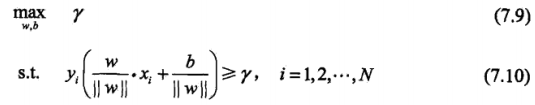
算法7.1

请看下面这个例子:
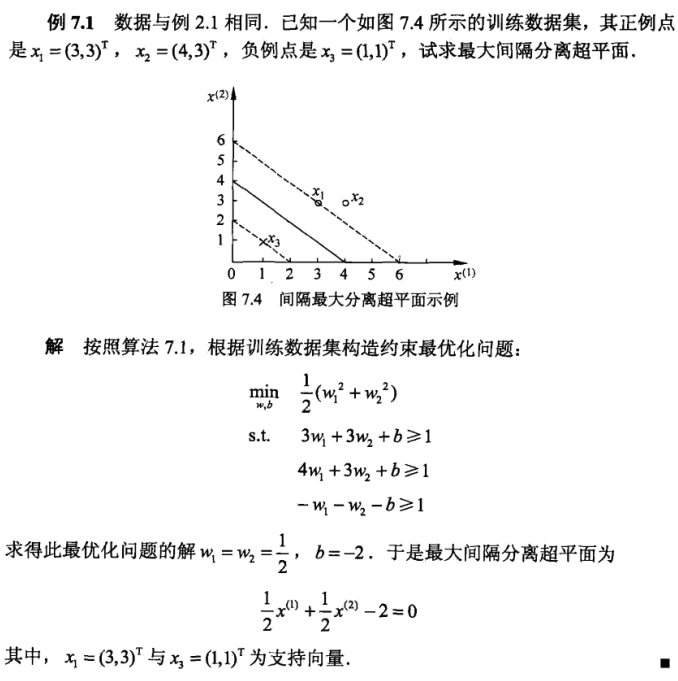
例7.1
7.1.4 学习的对偶算法
解法:
-
首先构建拉格朗日函数 L(w,b,a)
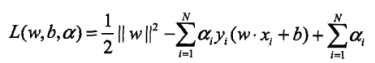
-
根据拉格朗日对偶性,转化为对偶问题(极大极小问题),如下所示:
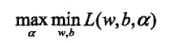
2.1 先求
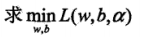
2.2 再求
算法7.2和定义7.4


7.2 线性支持向量机与软间隔最大化
7.2.1 线性支持向量机
训练数据中存在一些特异点,去除这些特异点后,剩下的大部分样本点组成的几何是线性可分的。 线性不可分意味着某些样本点 不能满足函数间隔大于等于1的约束条件(7.14)。为了解决这个问题,可以对每个样本点 引进一个松弛变量,使函数间隔加上松弛变量大于等于1。这样,越苏条件变为: 同时,对每个松弛变量,支付一个代价。这样目标函数由原来的
PS:C > 0 称为惩罚参数。
线性不可分的线性支持向量机的学习问题变成如下凸二次规划问题:
由上面公式可得定义7.5

7.2.2 学习的对偶算法


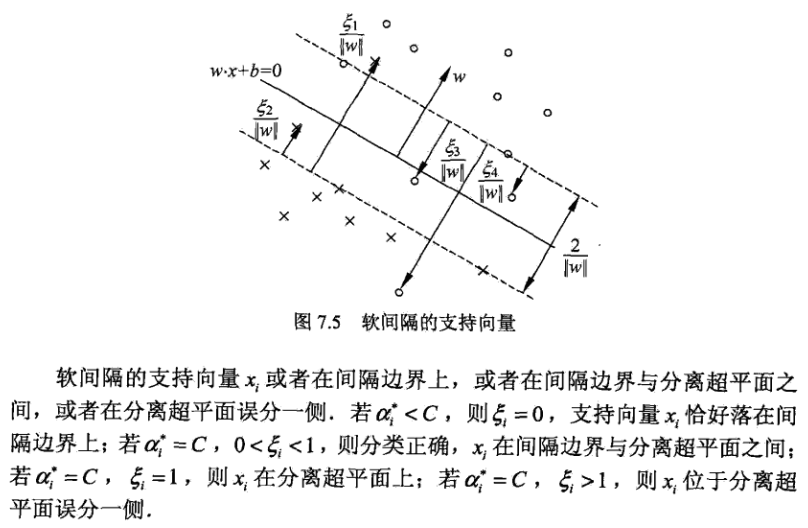
7.2.3 支持向量
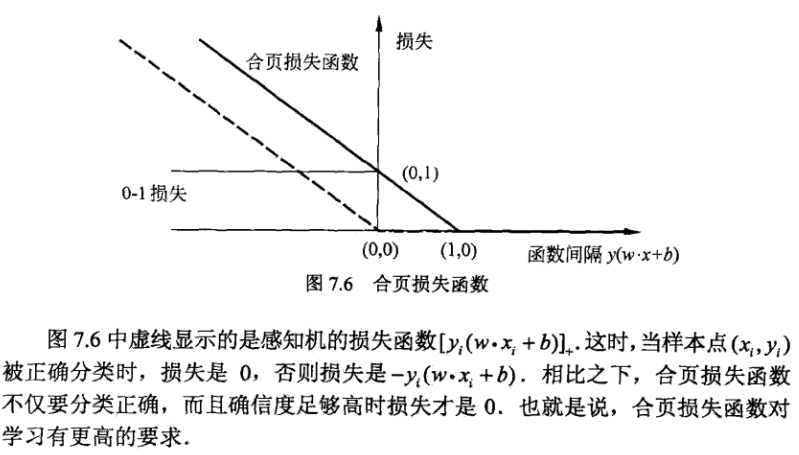
7.2.4 合页损失函数
线性支持向量机学习还有另外一种杰斯,就是最小化以下目标函数:
目标函数的第1项是经验损失或经验风险,函数:
称为合页损失函数(hinge loss function)。下标“+”表示取正值得函数。
定理7.4

7.3 非线性支持向量机与核函数
7.3.1 核技巧
核技巧:通过一个非线性变换将输入空间映射到一个特征空间,使得在输入空间中的超曲面模型对应于特征空间中的超平面模型。这样,分类问题的学习任务通过在特征空间中求解线性支持向量机久可以完成。
定义7.6(核函数) 设χ是输入空间(欧氏空间的子集或离散集),有设Η为特征空间(希伯尔空间),如果存在一个从χ到H的映射 使得对所有,函数K(x,z)满足条件
则称K(x,z)为核函数,φ(x)为映射函数,式中 φ(x).φ(z) 为内积。
核技巧的想法是:在学习与预测中只定义核函数K(x,z),而不显示的定义映射函数 φ(x)。 同样,分类决策函数中的内积也可以用核函数代替,而分类决策函数式成为
7.3.2 正定核
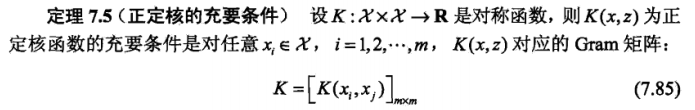

7.3.3 常用核函数

7.3.4 非线性支持向量分类机


7.4 序列最小最优化算法(sequential minimal optimization,SMO)
SMO算法要求解如下凸二次规划的对偶问题:
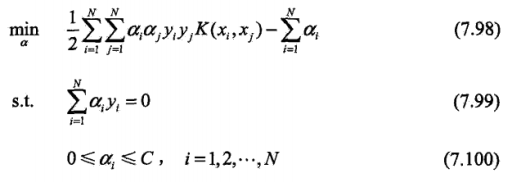
7.4.1 连个变量的二次规划的求解方法
略
7.4.2 变量的选择方法
略
7.4.3 SMO算法