“Action speak louder than words. ”
[TOC]
1 交叉熵代价函数
在介绍交叉熵代价函数之前,我们先看一个例子:
采用sigmod函数作为激励函数的感知机神经网络公式如下:
σ 对 z 的函数的函数图像如下:
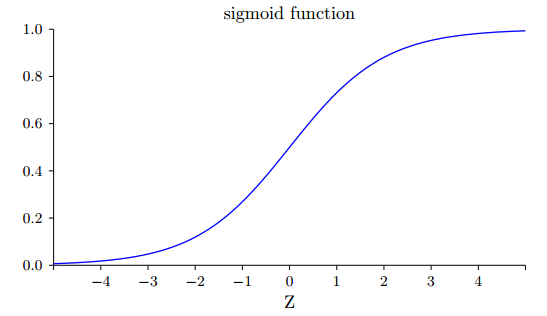
观察上图发现问题:当输出 接近1或者0的时候,曲线变得相当平,这时候 接近于0,根据公式(3)和(4)可知梯度向量和也接近0,梯度下降速度变得很慢。这样可能出现如下图所示的情况:
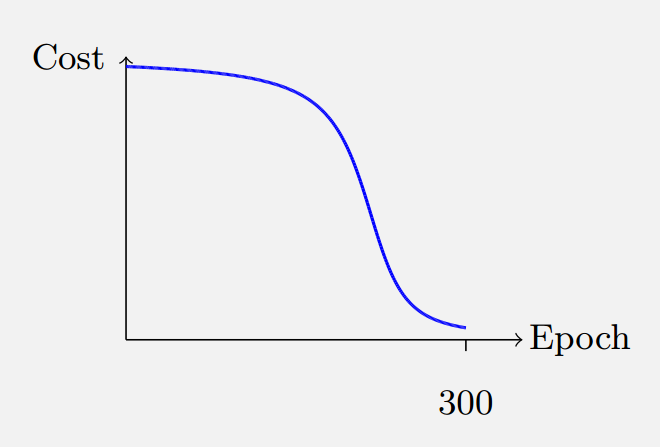
上图中在C接近1时,犯了明显错误的时候,梯度下降也十分缓慢——这并非我们期望得到的,我们希望:错误越明显(C的值越大),梯度下降越快!
1.1 什么是交叉熵代价函数
交叉熵代价函数如下图所示:
1.2 将交叉熵看做是代价函数的原因
第⼀,它是⾮负的, C > 0。可以看出:
- 公式 (5) 中的求和中的所有独⽴的项都是负数的,因为对数函数的定义域是 (0; 1);
- 求和前⾯有⼀个负号;
第⼆,如果对于所有的训练输⼊ x,神经元实际的输出接近⽬标值,那么交叉熵将接近 0。
1.3 交叉熵来源
交叉熵是推导而来的,并非直接定义而来。
观察公式(3)(4),可知梯度下降变慢和有关,如果去掉该项将得到的下面算式:
那么我们可以推测:假如一个新的代价函数满足公式(6)(7),那么久可以解决初始学习速度缓慢的问题。
推导过程:
首先针对单个样本进行推导
因为:
可得:
对比公式(7),可得:
对公式(11)进行积分,可得:
把公式(11)推广到n个样本条件下,则得到下面的公式:
令 constant = 0,就得到公式(5)
1.4 交叉熵代码示例
代码下载参考《基于感知机的手写数字识别神经网络》中的1.4部分。
运行下面代码:
1
2
3
4
5
6
7
8
9
10
11
12
# encoding = utf-8
"""test2.py
"""
import src.mnist_loader as mnist_loader
import src.network2 as network2
training_data, validation_data, test_data = mnist_loader.load_data_wrapper()
net = network2.Network([784, 30, 10], cost=network2.CrossEntropyCost)
net.large_weight_initializer()
net.SGD(training_data, 30, 10, 0.5, evaluation_data=test_data, monitor_evaluation_accuracy=True)
运行结果如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
C:\ProgramData\Anaconda3\envs\mlcc_gpu\python.exe E:/CODE/neural-networks-and-deep-learning-master/src/test2.py
Epoch 0 training complete
Accuracy on evaluation data: 9154 / 10000
Epoch 1 training complete
Accuracy on evaluation data: 9301 / 10000
Epoch 2 training complete
Accuracy on evaluation data: 9328 / 10000
Epoch 3 training complete
Accuracy on evaluation data: 9397 / 10000
Epoch 4 training complete
Accuracy on evaluation data: 9404 / 10000
Epoch 5 training complete
Accuracy on evaluation data: 9405 / 10000
Epoch 6 training complete
Accuracy on evaluation data: 9453 / 10000
Epoch 7 training complete
Accuracy on evaluation data: 9467 / 10000
Epoch 8 training complete
Accuracy on evaluation data: 9429 / 10000
Epoch 9 training complete
Accuracy on evaluation data: 9482 / 10000
Epoch 10 training complete
Accuracy on evaluation data: 9476 / 10000
Epoch 11 training complete
Accuracy on evaluation data: 9454 / 10000
Epoch 12 training complete
Accuracy on evaluation data: 9500 / 10000
Epoch 13 training complete
Accuracy on evaluation data: 9485 / 10000
Epoch 14 training complete
Accuracy on evaluation data: 9503 / 10000
Epoch 15 training complete
Accuracy on evaluation data: 9483 / 10000
Epoch 16 training complete
Accuracy on evaluation data: 9495 / 10000
Epoch 17 training complete
Accuracy on evaluation data: 9516 / 10000
Epoch 18 training complete
Accuracy on evaluation data: 9514 / 10000
Epoch 19 training complete
Accuracy on evaluation data: 9504 / 10000
Epoch 20 training complete
Accuracy on evaluation data: 9512 / 10000
Epoch 21 training complete
Accuracy on evaluation data: 9533 / 10000
Epoch 22 training complete
Accuracy on evaluation data: 9515 / 10000
Epoch 23 training complete
Accuracy on evaluation data: 9522 / 10000
Epoch 24 training complete
Accuracy on evaluation data: 9530 / 10000
Epoch 25 training complete
Accuracy on evaluation data: 9515 / 10000
Epoch 26 training complete
Accuracy on evaluation data: 9501 / 10000
Epoch 27 training complete
Accuracy on evaluation data: 9504 / 10000
Epoch 28 training complete
Accuracy on evaluation data: 9538 / 10000
Epoch 29 training complete
Accuracy on evaluation data: 9540 / 10000
Process finished with exit code 0
2 柔性最大值(softmax)
柔性最⼤值的想法其实就是为神经⽹络定义⼀种新式的输出层来避免S型函数的问题。开始时和 S 型层⼀样的,⾸先计算带权输 。不过,这⾥我们不会使⽤ S 型函数来获得输出。⽽是,在会在这⼀层上应⽤⼀种叫做柔性最⼤值函数在 上。根据这个函数,第 j 个神经元的激活值就是 : 其中,分⺟中的求和是在所有的输出神经元上进⾏的。 根据上式, 是 其在L层的比重。
对公式(14)求w和b的偏导: