“Action speak louder than words. ”
[TOC]
1 反向传播
反向传播的过程其实就是计算代价函数的梯度(求导计算)得过程。然后根据求得梯度,更新参数来降低代价。
代价函数是是定义在整个训练集上的,是所有样本误差的平均,也就是损失函数的平均。
损失函数是单个样本的误差。
代价函数C和w的关系如下所示:
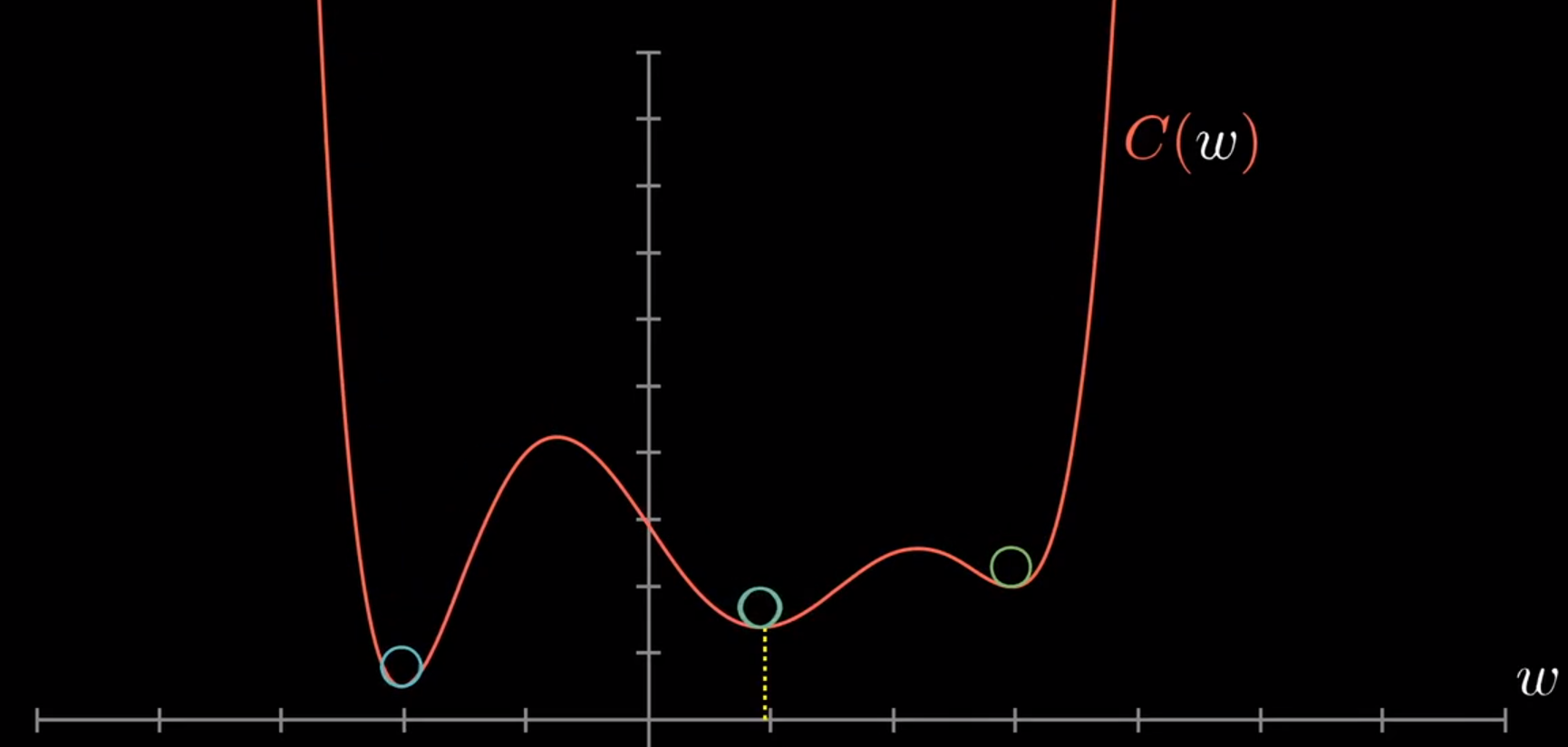
根据图片可知,常见的梯度下降法由于初始值不同,会落在不同的局部最小值上(而非全局最小值)。
1.1 什么是前向传播和反向传播
下面是3Blue1Brown的深度学习之反向传播算法 上/下 Part 3 ver 0.9 beta。里面生动讲解了方向传播的基本概念和计算过程,建议大家先看一下。
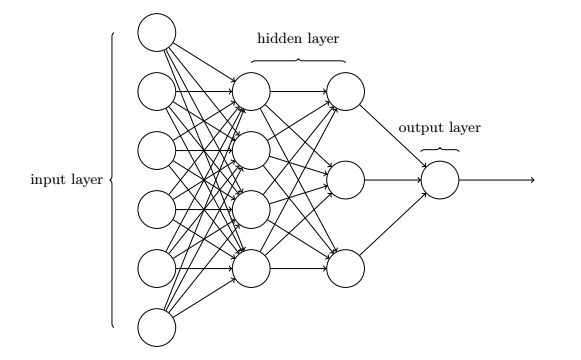
前向传播方向:输入层 » 隐藏层 » 输出层,目的是输出目标结果,如下图所示:
反向传播方向:输出层(代价函数) » 隐藏层 » 输出层,目的是调整参数(w和b),如下图所示:
1.2 反向传播的计算
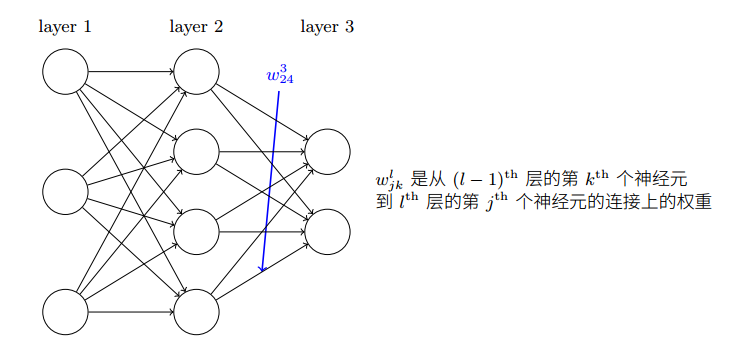
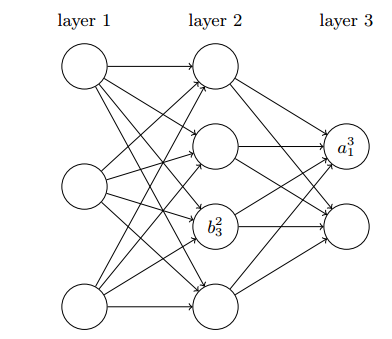
使⽤ 表⽰从 (l - 1) 层的第 k 个神经元到第 l 层的第 j 个神经元的链接上的权重;使⽤ 和 分别表⽰第 l 层第 j 个神经元的 偏置 和 激活值。下⾯的图清楚地解释了这样表⽰ 的含义: 设
以感知机为例,采用梯度下降法,损失函数为平方损失函数(针对单个样本有 ),则有:
设输出层误差为 ,则: 令 $ \nabla_a C = \{ \frac{\partial C}{\partial a^L_j} \ | \ j \in J \}$ (将$ \nabla_a C $ 看成L层上是 C 关于J个输出 激活值的改变速度的集合,用向量表示 ),则公式(4)可推导出:
注:⊙ 是Hadamard 乘积,表⽰按元素的乘积。
1.2.1 反向传播计算过程
步骤一:公式(5)代入公式(3)这样就可以计算出最后一层(输出层)的误差: 得到最后一层的误差 ,再分别对 和 求导,可得到下面两个算式: 得到最后一层参数和的梯度。
步骤二:L-1 层的的误差 如下:
代入公式(7)(8)可以得到倒数第二层参数和的梯度。步骤三:重复 步骤二 的过程,最后可以获得神经网络每一层关于参数和的梯度。
步骤四:用下面的算式更新参数和:
- 注: 是学习速率*
该反传播算式总结如下:

可以结合博客《基于感知机的手写数字识别神经网络》中的代码一起加深理解。