“Action speak louder than words. ”
[TOC]
、
1 权重初始化
需要注意下面两点:
- 独⽴随机变量和的⽅差,是每个独⽴随机变量⽅差的和;
- ⽅差是标准差的平⽅。
PS:可以用公式 D(kX) = k²D(X)证明上面注意点第一条
1.1 标准正太分布初始化问题
假设某一个隐藏层有10000个节点,并且从前面一层得到的输入 都非0,用标准正太分布初始化这一层的参数w和b;对于这一层的输出,参考公式 ,再结合上面是注意点,z 是⼀个均值为 0 标准差为 的⾼斯分布。这是一个很平缓的高斯分布,如下图所示:
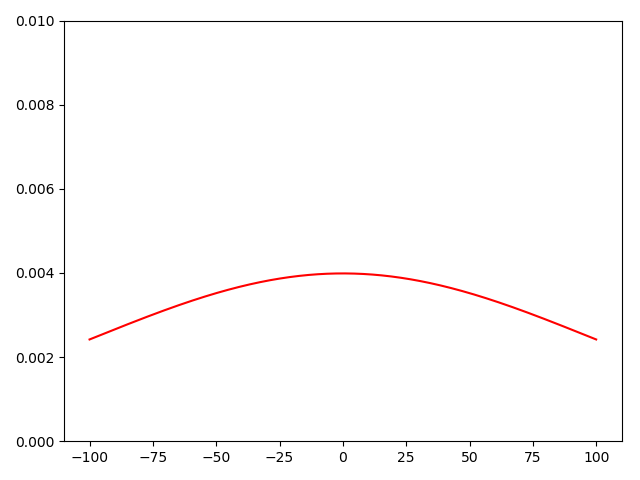
生成该图的代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
import numpy as np
import matplotlib.pyplot as plt
import math
def normal_distribution(x, mean, sigma):
return np.exp(-1 * ((x - mean) ** 2) / (2 * (sigma ** 2))) / (math.sqrt(2 * np.pi) * sigma)
mean, sigma = 0, np.sqrt(10001)
x = np.linspace(-100, 100, 1000)
y = normal_distribution(x, mean, sigma)
plt.plot(x, y, 'r', label='m=0,sig=1')
plt.ylim((0, 0.01))
plt.show()
根据上图,我们可以判断该层输出|z|很大,这会造成σ(z) 接近0或者1。σ(z) 图像如下:
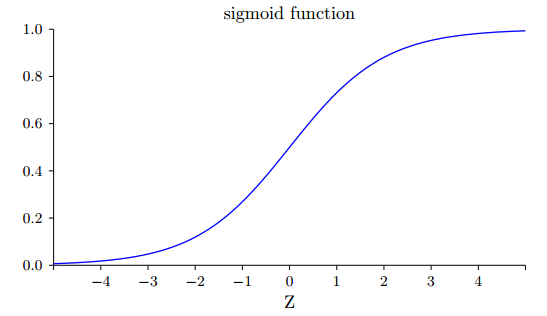
此时该层输出接近饱和,导致该层的学习速度变慢。
1.2 如何初始化权重
假设神经网络L层有n个输入,m个输出,那么对于该层:
- 使用均值为0,标准差为 的高斯分布来初始化这些权重(w),生成一个 m*n 的矩阵;
- 对于偏置(b),使⽤均值为 0 标准差为 1 的⾼斯分布来进⾏初始化,生成一个 m*1 的矩阵。
代码表示如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
def default_weight_initializer(self):
"""Initialize each weight using a Gaussian distribution with mean 0
and standard deviation 1 over the square root of the number of
weights connecting to the same neuron. Initialize the biases
using a Gaussian distribution with mean 0 and standard
deviation 1.
Note that the first lamer is assumed to be an input lamer, and
bm convention we won't set anm biases for those neurons, since
biases are onlm ever used in computing the outputs from later
lamers.
"""
self.biases = [np.random.randn(m, 1) for m in self.sizes[1:]]
self.weights = [np.random.randn(m, n)/np.sqrt(n)
for n, m in zip(self.sizes[:-1], self.sizes[1:])]
1.3 标准正态分布初始化和改进后初始化效果对比
代码下载参考《基于感知机的手写数字识别神经网络》中的1.4部分。
运行代码 \neural-networks-and-deep-learning-master\fig\weight_initialization.py
得到对比数据如下:

根据上图,我们可知:虽然2种初始化方法分类准确率一样,但是,改进后的方法带来的是速度的提升。