Take control of your own destiny
[TOC]
、
1 梯度消失和梯度爆炸
早深层的神经网络中经常会遇到梯度消失和梯度爆炸问题,那么这是如何产生的呢?
1.1 举栗说明
这是个每一层只有一个神经元,深度为5的神经网络:

这个网络采用 S 型激活函数,表示第j层的加权和,表示第j层的输出,那么代价函数 C 对的偏导表达式如下:

我们再看一下 S 型激活函数的密度函数:
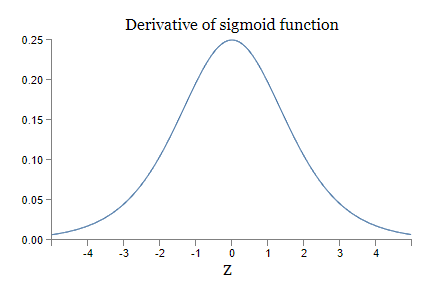
可知:$\sigma’(z_j) \leq 1/4$;
如果用标准正态分布初始化$w_j$,那么大部分满足$|w_j| < 1$,从而导致:$|w_j \sigma’(z_j)| < 1/4$。
这样的神经网络随着深度的增加,反向传递的结果会指数级的下降,从而导致梯度消失。
那么梯度爆炸又是如何产生的呢?观察 $|w_j \sigma’(z_j)|$,会发现如果w足够大,比如设 w = 100 ,那么满足$\sigma’(z_j) > 1$,这样的神经网络随着深度的增加,反向传递的结果会指数级的上升,从而导致梯度爆炸。
1.2 解决办法
根据上面的例子,我们知道梯度问题的罪魁祸首是$|w_j \sigma’(z_j)|$,那么我们可以:
(a)使用ReLU 或者其他激励函数替换S 型激励函数。ReLU函数图如下:

可知ReLU大于0部分倒数恒为1,不会产生梯度丢失或者爆炸。同时该函数相比S型函数加简单,加快了正向传播和反向传播的速度,加速了网络的训练。
(b)初始化参数w时,注意满足,参考《改进神经⽹络的学习⽅法(四)–超参数调节》。