The best preparation for tomorrow is doing your best today.
[TOC]
、
1 卷积神经网络(convolutional networks)
回顾之前的《基于感知机的手写数字识别神经网络》中的例子,基于感知机的神经网络把每个特征一视同仁,放在一起和隐藏层全连接,最后我们得到一个正确率94+%神经网络,结构如下所示:
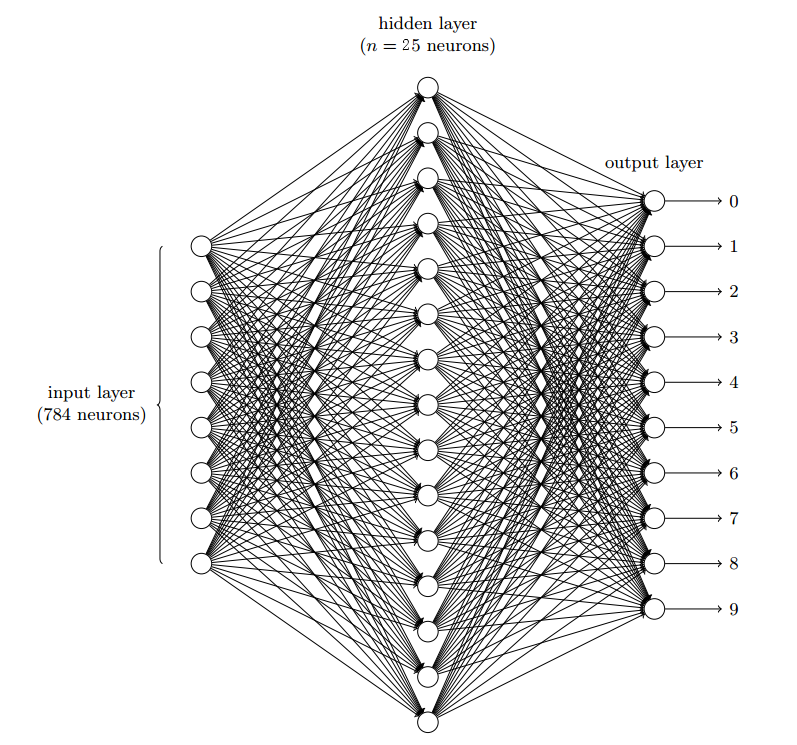
但是,所有特征放在一起,变成一个数列的形式,破坏了图像的空间概念:
-
图片每个像素有其唯一的位置,像素之间的关系应该是越近的相关性越大,越远的相关性越小;
-
对于一个图片,我们关注的特征可以是多个层面的,比如:轮廓,颜色;
-
一个数字图片按比例缩小一定倍数后,并不妨碍我们认出该数字;
-
and so on
那么根据图像的这些空间特征,构建一个更适合处理图像的神经网络——那就是CNN,结构如下图所示:
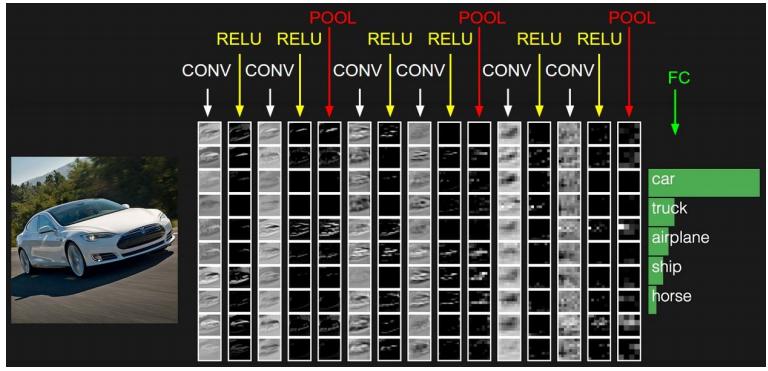
卷积神经网络的层级结构描述:
-
数据输入层/ Input layer
-
卷积计算层/ CONV layer
-
ReLU激励层 / ReLU layer
-
池化层 / Pooling layer
-
重复 n 遍 2~4 的结构
-
全连接层 / FC layer
-
相比感知机神经网络,该神经网络最大的不同是 卷积计算层 和 池化层。这涉及CNN的三种基本概念:局部感受野(local receptive fields), 共享权重(sharedweights),和混合(pooling)。
1.1 卷积计算层(CONV layer)
卷积层作用:用多个“过滤器“(filetr),从左往右,从上往下的过滤图片,最后每个”过滤器“都得到一个对应的图片。如下图所示:

那么过滤器是怎么工作的呢?如下图所示:
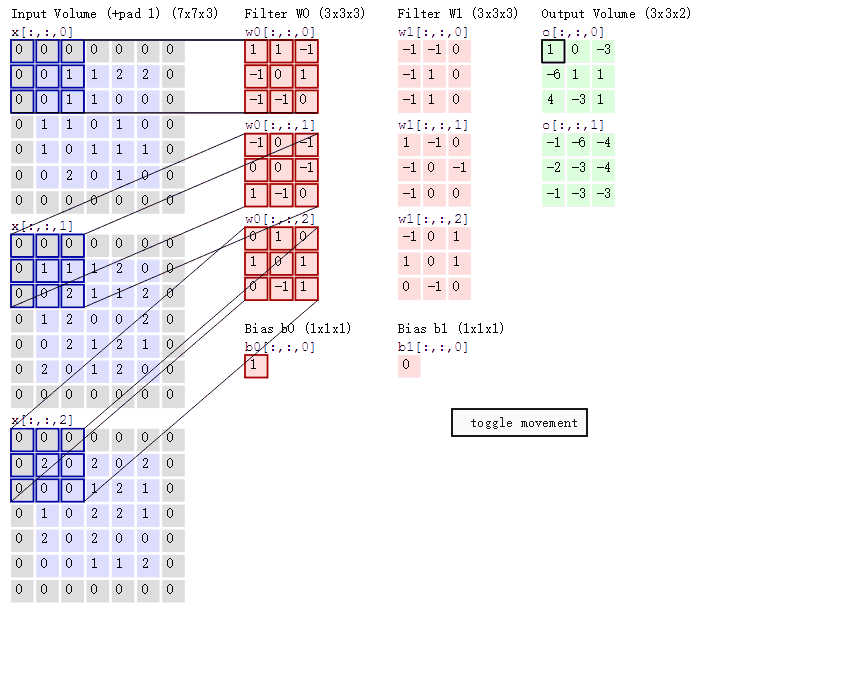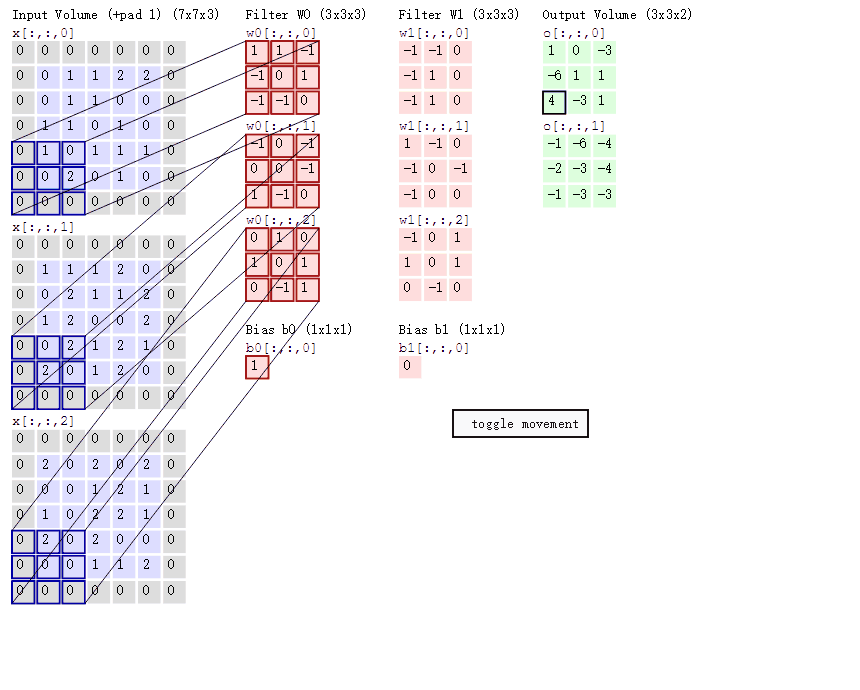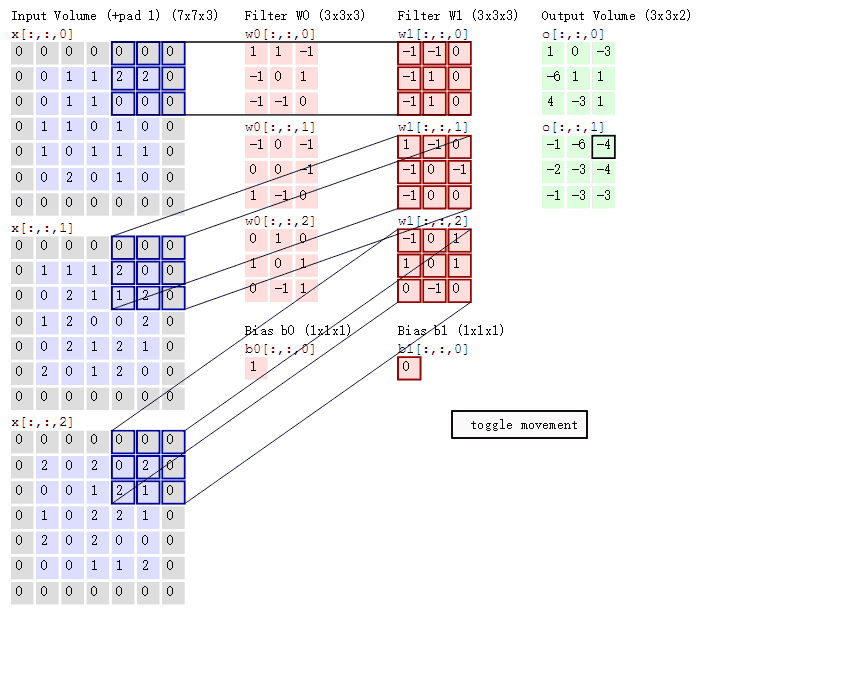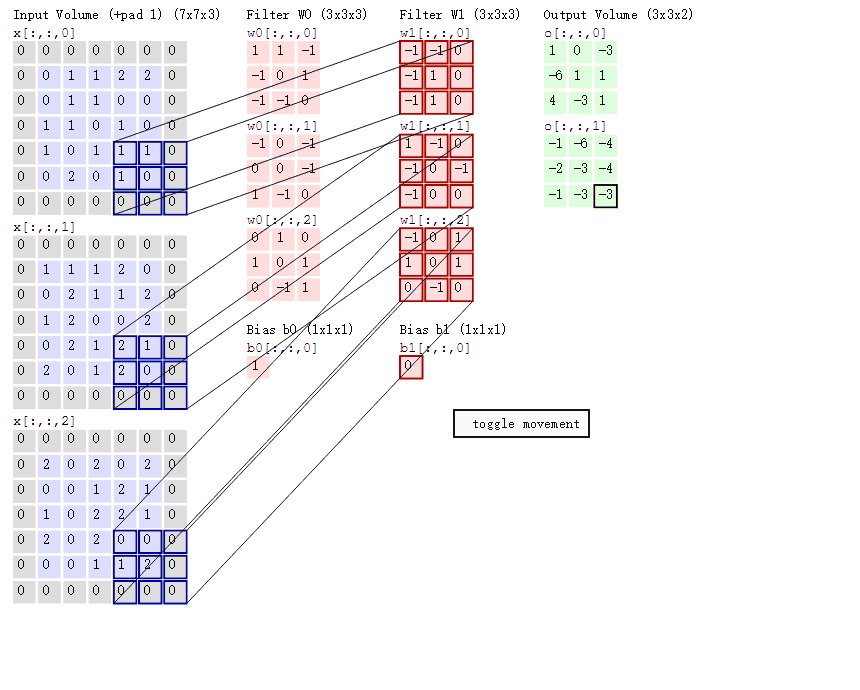

输⼊图像是一个5*5*3的彩色图片(因为是彩色的,所以深度为3)。每次蓝色框格(一个3*3*3的矩阵)只覆盖图像的一部分,该部分被称为隐藏神经元的局部感受野;蓝色框格每次移动的距离被称为步长(stride length,,上图中步长为1)。
根据上图,你会发现:每个5*5*3的图片使⽤相同的权重和偏置(比如是一个3*3*3的红色矩阵,是红色矩阵[1]),这便是共享权重和偏置 **。共享权重和偏置常备称做卷积核或者过滤器** 。
你肯定也注意到上图中5*5*3的图片外围填充了一堆0,这是卷积计算的一个方法——zero-padding,并非一定要填充。但是假如上面例子中把步长改为3,采用非填充方式(直接是5*5*3图片),那么只能获得左上角3*3*3部分的信息,其他地方的信息由于图片尺寸不够,被丢弃了。(
PS:建议采用padding
1.2 池化层(Pooling layer)
池化层相比卷积层好理解多了,它就干一件事:压缩图片尺寸,减少下一层的计算量;同时由于Pooling的同时,对丢弃一些相对不重要的信息,还能减少过拟合。
当然,压缩方式也是千奇百怪,常见的有:
- max-pooling(比如一个 24*24的图片 用 2*2 矩阵进行 max-pooling,其实是图片每个 2*2 像素部分取最大值,最后变成一个 12*12 的图片)
- L2 pooling (比如一个 24*24的图片 用 2*2 矩阵进行 L2 pooling,其实是图片每个 2*2 像素部分平⽅和的平⽅根 ,最后变成一个 12*12 的图片)
1.3 建立一个卷积神经网络
代码下载参考《基于感知机的手写数字识别神经网络》中的1.4部分。
运行代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
from src.network3 import ReLU
import src.network3 as network3
from src.network3 import Network
from src.network3 import Network
from network3 import ConvPoolLayer, FullyConnectedLayer, SoftmaxLayer
training_data, validation_data, test_data = network3.load_data_shared()
mini_batch_size = 10
net = Network([
ConvPoolLayer(
image_shape=(mini_batch_size, 1, 28, 28),
filter_shape=(20, 1, 5, 5),
poolsize=(2, 2), activation_fn=ReLU),
ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12),
filter_shape=(40, 20, 5, 5),
poolsize=(2, 2),
activation_fn=ReLU),
FullyConnectedLayer(n_in=40*4*4, n_out=100, activation_fn=ReLU),
SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
net.SGD(training_data, 60, mini_batch_size, 0.03,
validation_data, test_data, lmbda=0.1)
将得到一个分类准确为99%的卷积神经网络。