“What is a neural network? To get started, I’ll explain a type of artificial neuron called a perceptron. Perceptrons were developed in the 1950s and 1960s by the scientist Frank Rosenblatt, inspired by earlier work by Warren McCulloch and Walter Pitts. Today, it’s more common to use other models of artificial neurons - in this book, and in much modern work on neural networks, the main neuron model used is one called the sigmoid neuron. ”
[TOC]
第2章 感知机
感知机(perceptron,模拟人类视神经控制系统的图形识别机)是二类分类的线性分类模型,其输入为实例的特征向量,输出为实例的类别,取+1和-1二值,属于判别模型。
2.1 感知机模型
2.1.1 感知机原始模型
先举个例子介绍一下感知机的原始模型,例子如下:
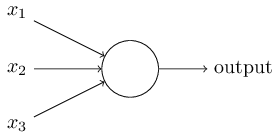
⽰例中的感知器有三个输⼊,。通常可以有更多或更少输⼊。 Rosenblatt 提议⼀个 简单的规则来计算输出。他引⼊权重, ,表⽰相应输⼊对于输出重要性的实数。神经 元的输出, 0 或者 1,则由分配权重后的总和 ⼩于或者⼤于阈值决定。和权重⼀样,阈值是⼀个实数,⼀个神经元的参数。⽤更精确的代数形式: 上面代数形式的条件可以用向量点乘的形式来简化;同时把阈值移到不等式的另⼀边,并⽤感知器的偏置 b ≡ -threshold 代替。 简化后如下:
*PS:这⾥ w 和 x 对应权重和输⼊的向量,b代表偏置向量。 *
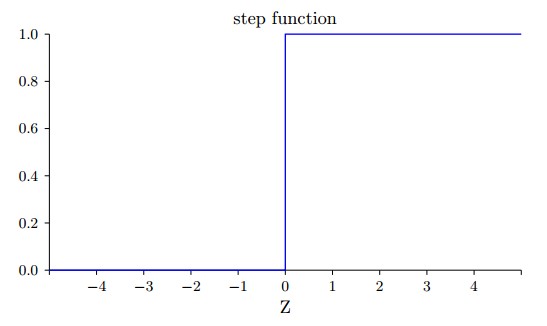
令 ,则 output (阶跃函数)如下图所示:
2.1.2 感知机的几何解释
线性方程 对应于特征空间中的一个超平面S,其中w是超平面的发向量,b是超平面的截距。这个超平面将特征空间划分成2个部分,位于2部分的点(特征向量x),分别被分为正、负 两类。因此,超平面S称为分离超平面(separating hyperplace)。如下图2.1所示:
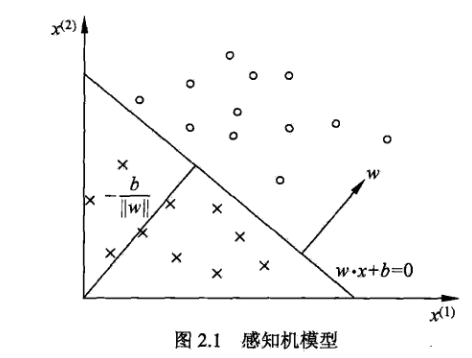
PS:关于该几何解释,如果不懂,可以搜索向量内积的几何解释
2.1.3 S形神经元
感知机算法对应神经网络的S形神经元
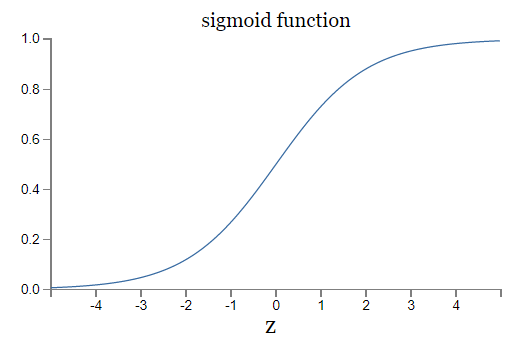
正如⼀个感知器, S 型神经元有多个输⼊, 。但是这些输⼊可以取 0 和 1 中的任意值,⽽不仅仅是 0 或 1。例如, 0.638 是⼀个 S 型神经元的有效输⼊。同样, S 型神经元对每个输⼊有权重 ,和⼀个总的偏置 b 。但是输出不是 0 或 1。相反,它现在是 σ(w · x + b),这⾥ σ 被称为 S 型函数,定义为: 把它们放在⼀起来更清楚地说明,⼀个具有输⼊ ,权重 ,和偏置 b 的 S 型神经元的输出是: S 型神经元的 output 关于 Z 函数如下图所示:
2.2 感知机学习策略
2.2.1 数据集的线性可分性
对于训练集,存在超平面 S ( w.x + b = 0) 能够将 T 的 正实例点 和 负实例点完全正确地划分到超平面的两侧(即:对任意的实例,都有;对任意 的实例,都有;),则称T为线性可分数据集;否则,称为线性不可分。
2.2.2 感知机学习策略
损失函数(任意一点x0到超平面S的距离):
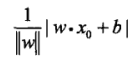 这里,||w||是w的L2范数,用于消除w,b同比增大后,求得数字也变大。
这里,||w||是w的L2范数,用于消除w,b同比增大后,求得数字也变大。
对于正确分类数据恒有: ;
误分类类数据恒有:;
对于无分类点集合M,则损失函数为:
2.3 感知机学习算法
2.3.1 感知机学习算法的原始形式
损失最小化,即求参数w,b, 使其为以下损失函数最小化问题的解
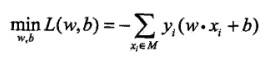
解题步骤:
- 该损失函数的梯度(对w,b单独求导):

- 随机选取一个误分类点,对w,b进行更新:

PS:其中 0 < η <= 1,称为学习速率。
- 重复1. 2. 直至无误分类点时结束;
算法2.1 感知机算法的原始形式

例 2.1
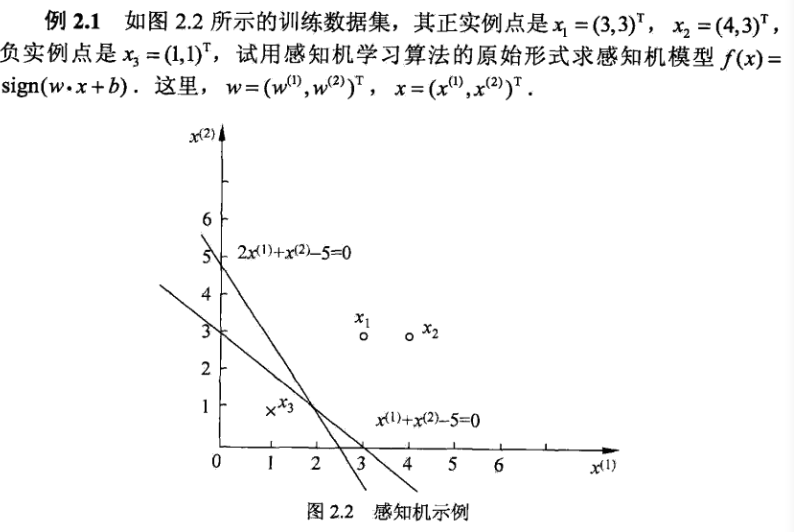
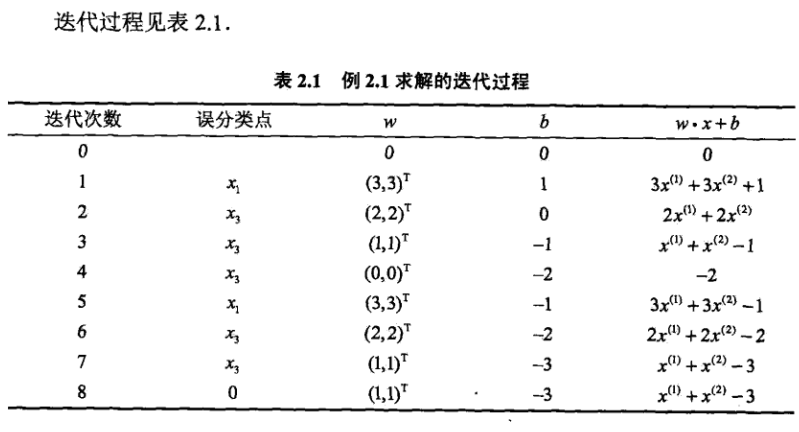
PS:感知机学习算法由于采用不同的处置或选取不同的误分类点,解可以不同。
2.3.2 算法的收敛性


该定理说明k有上界。
2.3.3 感知机学习算法的对偶形式


例 2.2


PS:表2.2和书本上的不一样,书本上的有错误,该博客的表2.2是修改后正确版本。